
Bayesian Filtering
Bayesian filtering is a classification method for defining categories for documents. It has gained large attention as an efficient way to filter spam.
As a machine learning technique, it requires training to work. In the beginning, a large corpus of good messages (ham) and bad messages (spam) are fed into the engine. The system counts the occurences of words in the good and bad corpus.
After a while, it learns the probability that a certain word will appear in a good or bad mail message. For example, the word "nigeria" will appear much more in spam messages than in ham messages. This is the essence of the technique.
Our Bayesian filtering attempt tries to classify documents as well, either as good design (ham) or bad design(spam). We hope the computer will learn to recognize good design. Once he knows what good design is, he can just generate thousands of designs, until one passes his own spam filter.
First attempt: value filtering
We wrote our own classification program that determines itself what good design is. In our program, everything above the blue line is good, and everything below it is bad:

The basic idea is that the values are the core of the algorithm, and they need fine-tuning.
Each rectangle is written as a program in itself, and classified as good or bad (depending on its position). Then, a parser counts the occurrences of the four values of the rectangle function: x, y, width and height. It doesn't filter on which parameter is which: it just counts numbers.
The number distribution is as follows:
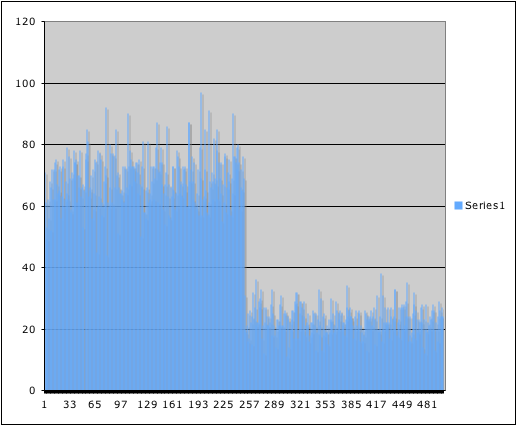 Ham number distribution
Ham number distribution
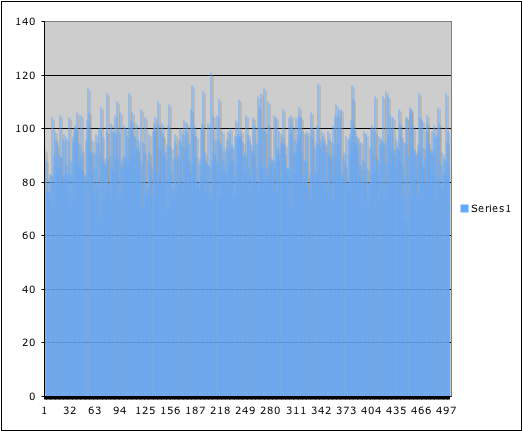 Spam number distribution
Spam number distribution
The ham numbers show a (noisy) preference for the upper values, while the spam numbers have no preference at all. Not too good.
Context-sensitive classification
Our next attempt tries to give context to each number: make seperate maps for each occurence of a number in the string, and compare them. This has the problem that all the programs should look exactly the same.
